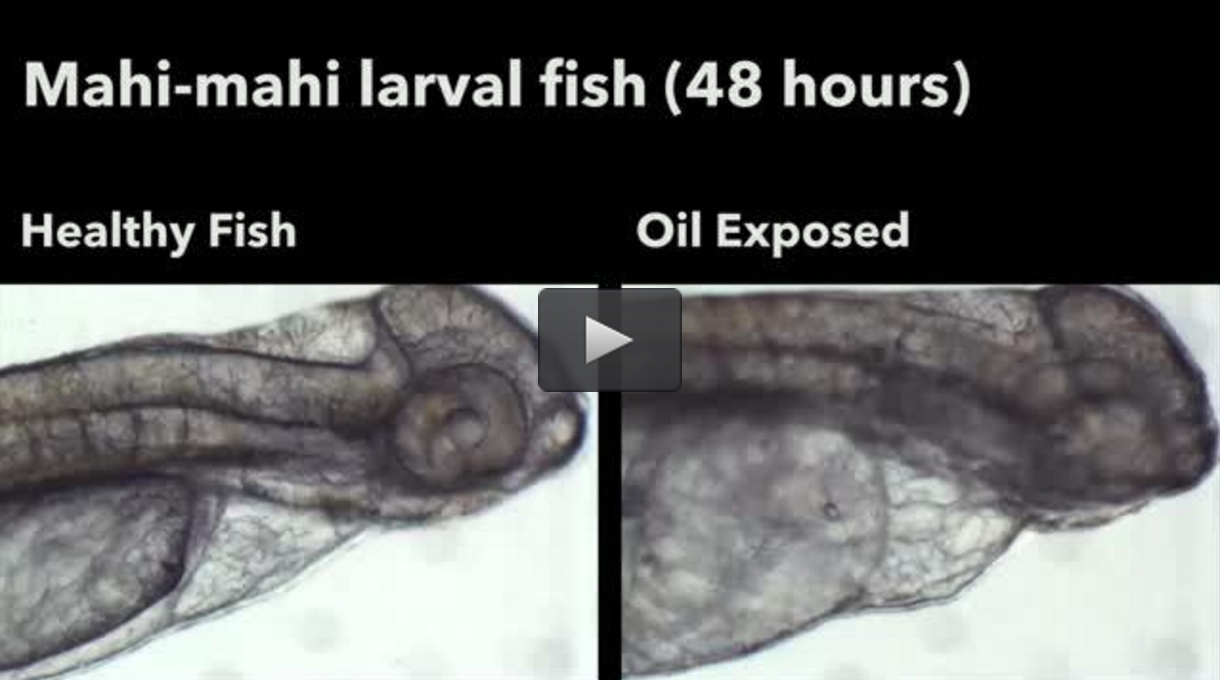









Click here to read the full interview.
Excerpt:
FLG: As an observer, it’s been fun to see so many new companies come into this space with their solutions. I know that you guys at ONRAMP believe very strongly in your platform and are actively encouraging people to trial it out for free. What would you say really sets you guys apart from the crowd?
TW: After looking at most of our “competitors” (which I use with a smile from the latin root: “to strive together”), my team as identified how we are currently the only ones that are bringing a converged big data platform to genomics analysis and storage. We enable the best of both worlds, a highly scalable Software as a Service that is deployed on-site for our customers, so they get the performance and security of an onsite system that’s scalable, with the same economics of a cloud-based solution. Our customers want a solution that will not just last for the current grant cycle, but will grow and scale as their data expands dramatically and their needs evolve.
We built out a comprehensive suite of genomics analysis capabilities that provide powerful bioinformatic pipelines that are both easy to use and fully capable of customization. These analysis pipelines are auditable and highly repeatable. Moreover, all customer data is stored at the customer site, in a highly-resilient and protected scalable storage system.
And this is just the beginning, because our platform also includes a full analytics engine powered by R, Hadoop and Spark. Through these technologies, we enable our customers to harness all their valuable genomic data, no matter where or how it is stored in their system. This is the key to enabling population scale insights.
FLG: What do you anticipate to be the next set of challenges in genomics as the field continues to develop?
Response: The industry is still operating with too many silos. This is one of the fundamental challenges to any industry, but is especially constraining to the field of genomics. We need to be adapting new technologies to solve the new and ever more complex problems that inevitably arise for researchers in our field. Neither the field, nor its researchers are ever standing still – that’s why we’ve built a high degree of flexibility into our solution. This foundation allows users to integrate data from different sequencing technologies and diverse experiments from RNA expression to DNA methylation, and enables them to update their analyses as their research progresses, the industry expands, and knowledge bases grow.