







Earlier this month, we launched NanoString Masterclass Series, designed to enhance scientific understanding and practical skills in advanced nCounter data analysis. Dr. Ryan Friese (VP of Rosalind Customer Experience) hosts the series to share his best practices from years of working hands-on with scientists in BioPharma and Academia as a Field Application Scientist for NanoString.
Video Highlights (5 mins) - access the FULL replay below

Mastering Custom Normalization: Insights from Rosalind’s Masterclass Series
In the dynamic field of gene expression analysis, the precision of data normalization can dramatically influence the accuracy of scientific outcomes. Recognizing the critical nature of this process, Rosalind’s second session of the Masterclass series delved into the sophisticated world of custom normalization, providing participants with an in-depth understanding of how to refine and enhance their nCounter gene expression data.
The Significance of Custom Normalization
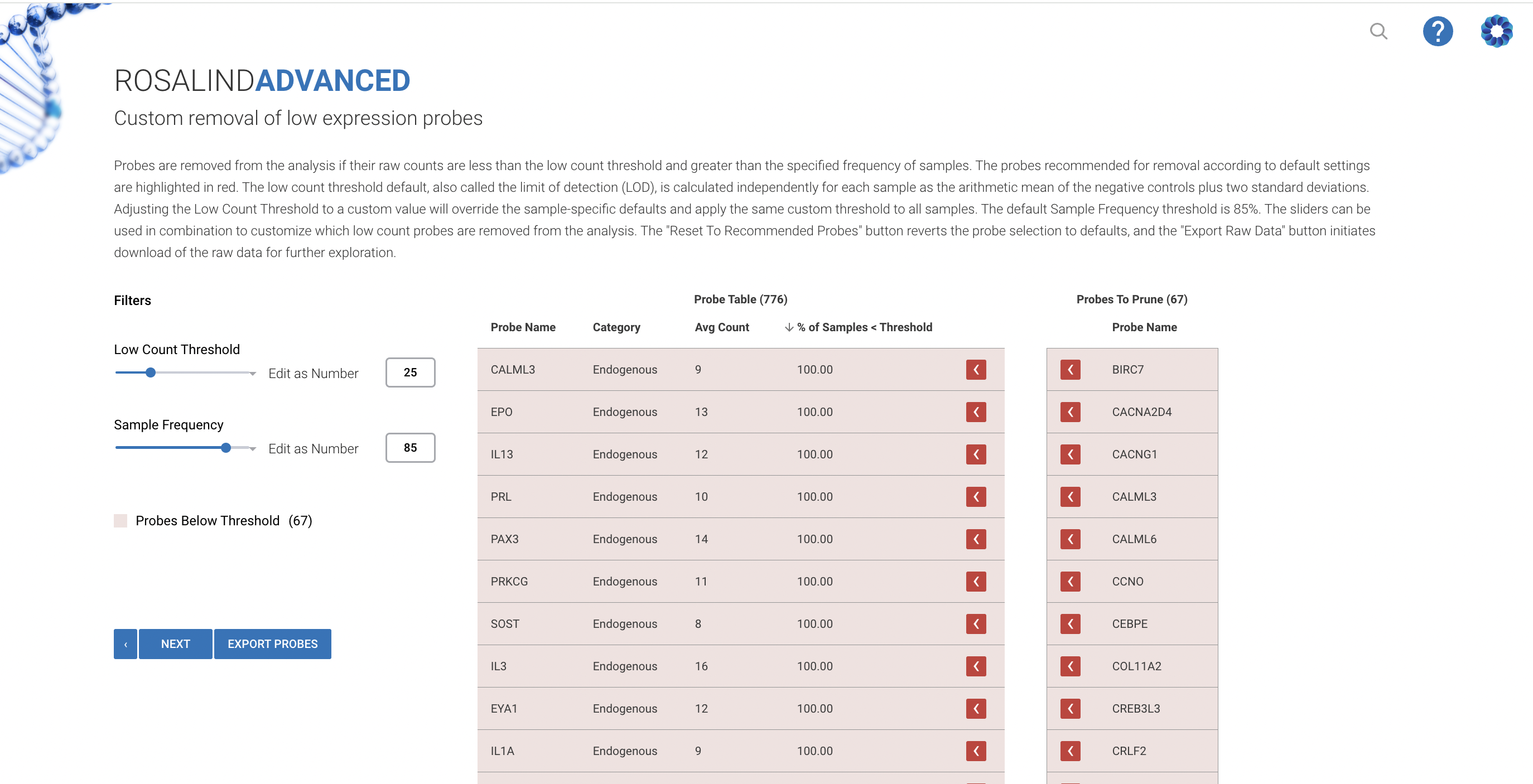
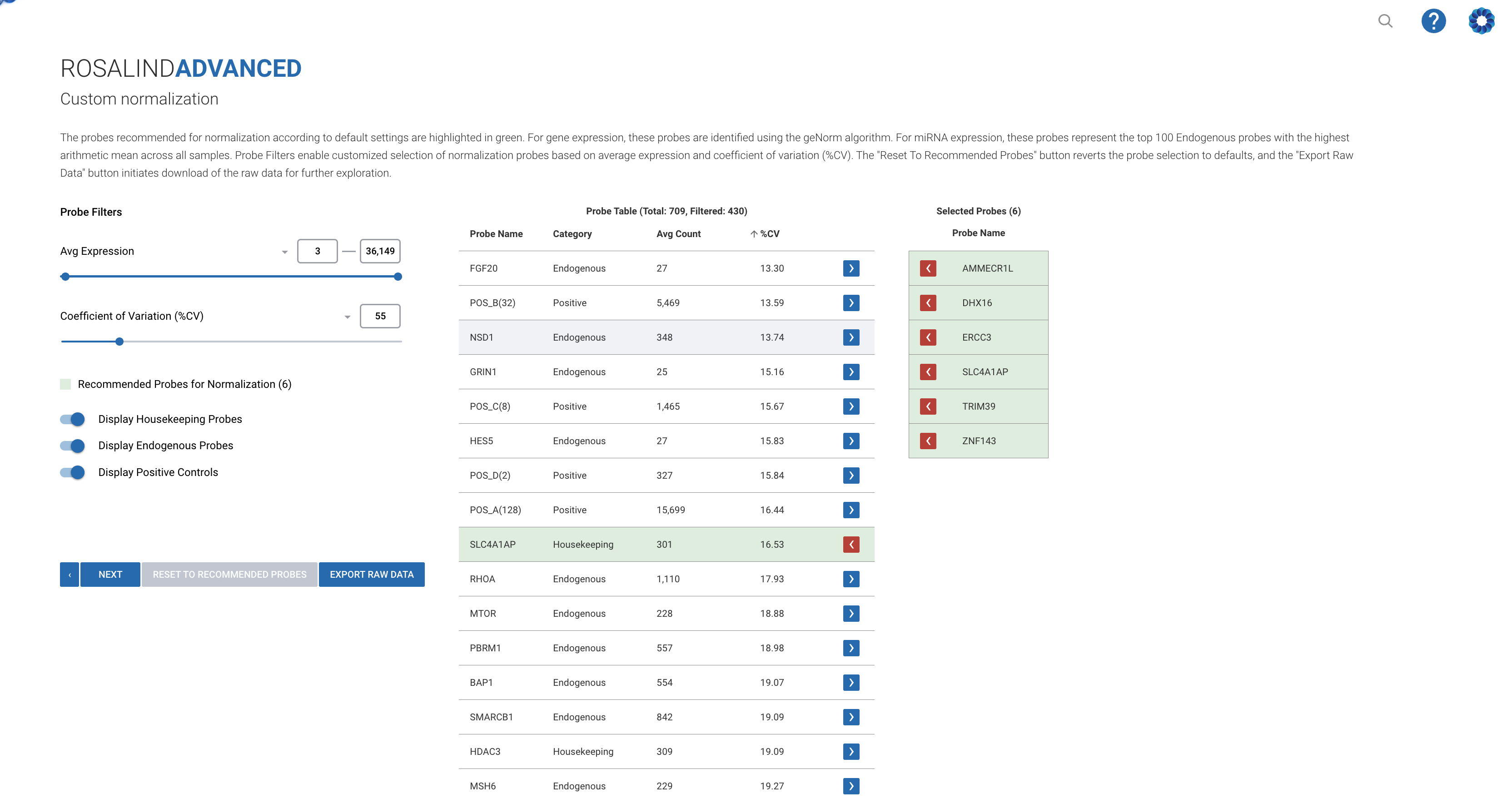
Custom normalization stands as a cornerstone technique for researchers aiming to ensure the reliability and relevance of their experimental data. It involves adjusting the expression levels of genes across samples to account for variations that do not relate to biological differences, such as technical disparities in sample processing or batch effects. By implementing custom normalization, scientists can minimize these confounding factors, bringing forth the true biological signal of interest.
Advanced Tools and Techniques Demonstrated
The session highlighted Rosalind’s advanced data analysis capabilities, particularly focusing on how the platform facilitates a more nuanced approach to normalization. Participants were introduced to an array of tools designed to tailor normalization processes to their specific research needs. This includes the selection of appropriate normalization factors based on statistical robustness and biological relevance, which ensures consistency across different experiments and datasets.
Practical Applications and Best Practices
Through practical examples and step-by-step tutorials, the masterclass not only illustrated the process of setting up custom normalization but also emphasized the best practices to follow. Attendees learned how to:
- Select the most stable reference genes from a panel, crucial for reducing variability and enhancing the comparability of results.
- Implement algorithm-driven approaches like Rosalind’s proprietary methods that intelligently determine the optimal normalization strategy based on the dataset’s unique characteristics.
- Assess the impact of chosen normalization methods on data interpretation, thereby ensuring that subsequent analyses lead to valid scientific conclusions.
Empowering Researchers with Enhanced Capabilities
By integrating these advanced methods into Rosalind’s user-friendly platform, the session underscored Rosalind’s commitment to empowering scientists. The tools presented are designed to not only simplify the normalization process but also to provide researchers with the confidence that their data analysis is both accurate and reproducible.
Conclusion
As the Masterclass series continues to unfold, each session builds on the last to equip researchers with the knowledge and tools necessary for cutting-edge gene expression analysis. Custom normalization, as detailed in this second session, plays a pivotal role in advancing research by providing a foundation for reliable data interpretation. Participants left the session equipped to tackle their data with newfound expertise, ready to uncover deeper biological insights.
For those interested in exploring these advanced capabilities, Rosalind’s platform offers an array of features that support every step of the gene expression analysis process. Whether you are a seasoned researcher or new to the field, Rosalind’s comprehensive suite of tools and educational resources can significantly enhance the efficiency and impact of your research endeavors.
Stay tuned for more insights from upcoming sessions, and explore how you can elevate your research with Rosalind’s innovative solutions. For more information, visit our Masterclass Series page. (edited)
Join the NanoString Masterclass Series
We are excited to continue this series with more in-depth explorations of other aspects of NanoString data analysis. Stay tuned for future sessions where we will cover topics like data integrity, scalability of experiments, and more.